地址:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9007361
论文还没研究透,有待深入,不太清楚具体怎样实现的
特点:在随机森林框架内提出了节点测试
注:随机森林由很多决策树组成。当我们进行分类任务时,新的输入样本进入,就让森林中的每一棵决策树分别进行判断和分类,每个决策树会得到一个自己的分类结果,决策树的分类结果中哪一个分类最多,那么随机森林就会把这个结果当做最终的结果。
Contribution:
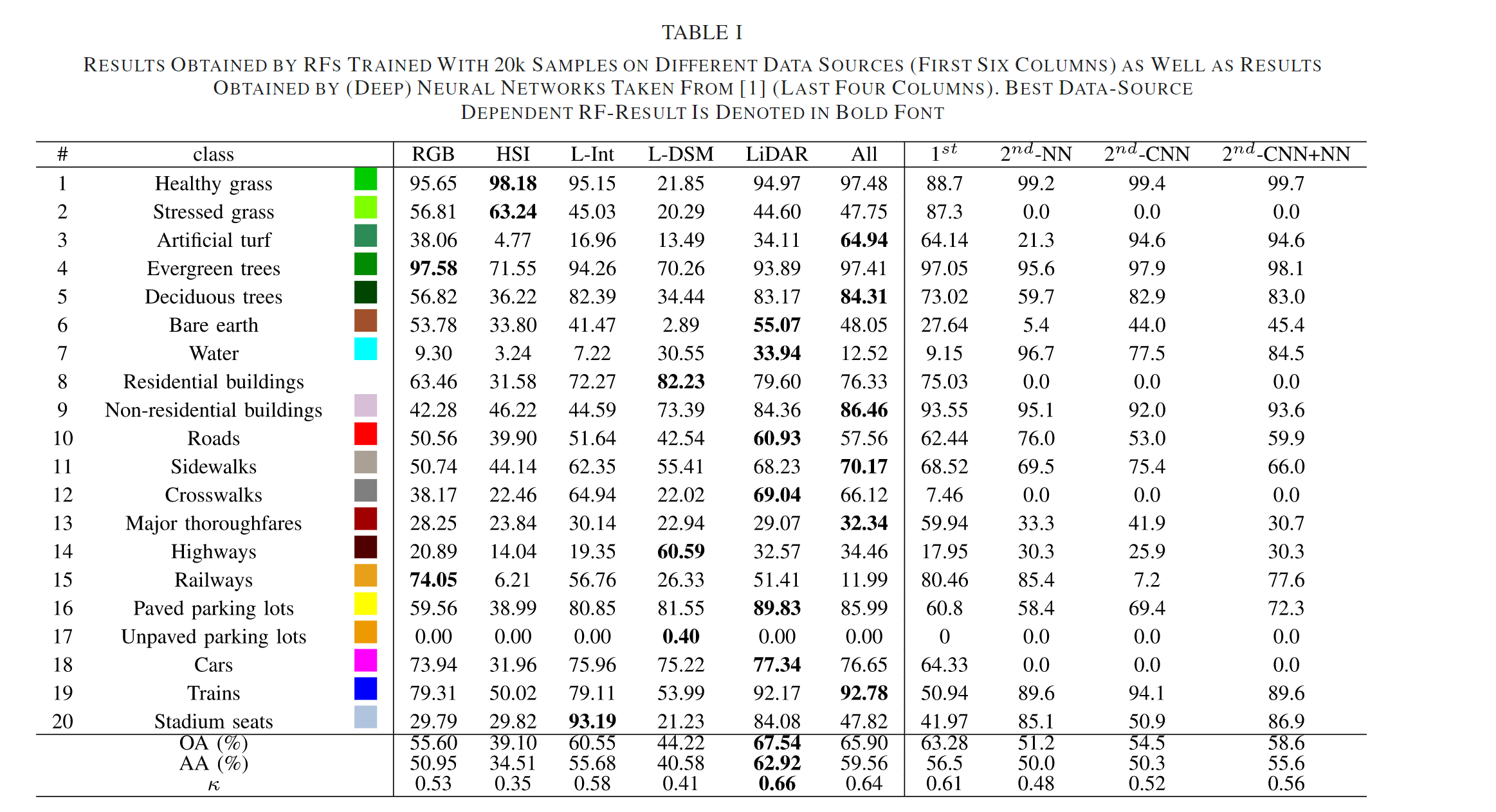
1、本文提出了一个基于随机森林(RF)的单个的分类器,该分类器可用于高光谱图像、RGB图像、基于LiDAR的图像数据,或这些图像的组合。此外,随机森林分类器可直接对图像数据进行特征提取,不需要经过预处理或特征提取。
2、本文所提的分类器可用来分析哪种不同的数据源对最终分类结果的贡献最大。
Data
DFC18(数据融合竞赛)提供在休斯顿大学获得的多模态光学遥感数据。该数据包括:
- 多光谱LiDAR数据,其地面采样距离(GSD)为0.5米
- 48个通道的高光谱图像,其GSD为1米
- 高分辨率RGB图像,其GSD为5cm
数据覆盖地理面积约4km²,约1.4km²用于训练
METHODOLOGY
随机森林的训练过程基于样本数为N的训练集D={(xi, yi)}, i=1, …, N,x:以每个像素点为中心的大小为ω×ω的patch方块;y:标签
高维样本的投影基于以下三个操作:
数据源的选择
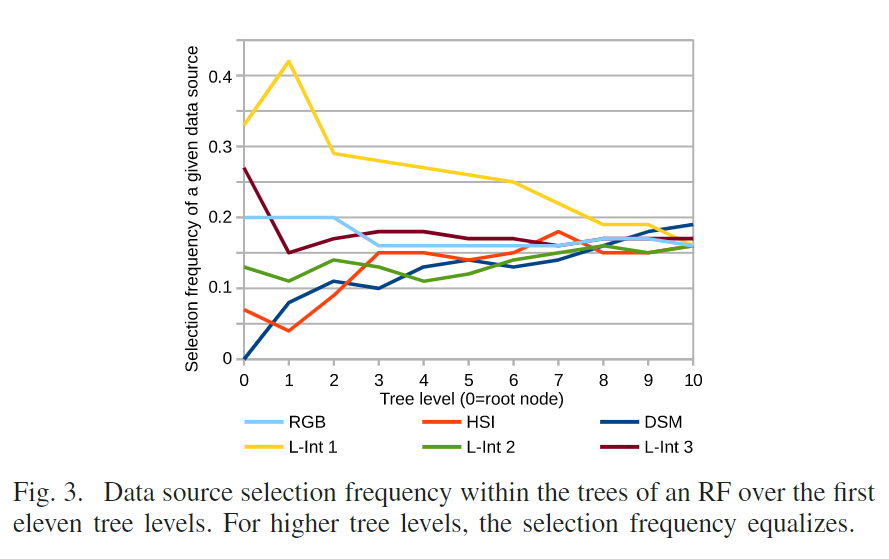
随机选取数据源作为输入,每个数据源的像素值构成一个向量R ^ds^ ,s为哪种数据源,ds为数据源的深度(LiDAR为1,HSI为48),节点测试函数中数据源的选择Φ是随机的
像素值的提取
选取一个数据源之后,随机选择样本x对应的patch中的1个或2个或4个区域。对这些区域使用操作φ,φ:随机操作——使用中心像素值,或取区域平均值/(对该区域每个维度求和后的最大值/最小值/中位数)
所提取像素值间的距离计算
最后一步完成高维样本x到单个标量x‘的映射。根据上一步每个patch中所提取的区域数的不同,有三种情况:
- 区域数为1:x’ = d(φ1(Φ(x)), v),v为一个随机参考值
- 区域数为2:x’ = d(φ1(Φ(x)), φ2(Φ(x)))
- 区域数为4:x’ = d(φ1(Φ(x)), φ2(Φ(x))) - d(φ3(Φ(x)), φ4(Φ(x))),
其中d的定义取决于数据源:
- LiDAR:d(a, b) = a-b 或者 d(a, b) = |a-b|
- RGB:a、b为三维数据,对不同颜色空间(颜色向量)使用欧氏距离
- HSI:使用光谱统计之间的差异,例如平均值,标准偏差,偏度,峰度和最小/最大/中值,或者矢量距离度量,例如欧几里得距离或逆相关等,然后每个样本点随机选择这些方法
每个内部节点n创建了种潜在的测试功能,划分局部数据Dn ∈ D为DnL左子节点和DnR右子节点。其划分通过以下公式评估:
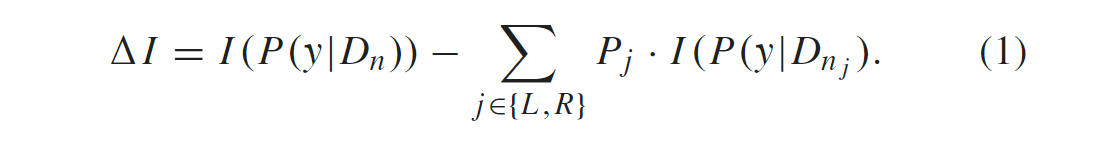
EXPERIMENTS
本实验基于30棵决策树(最大50棵)。
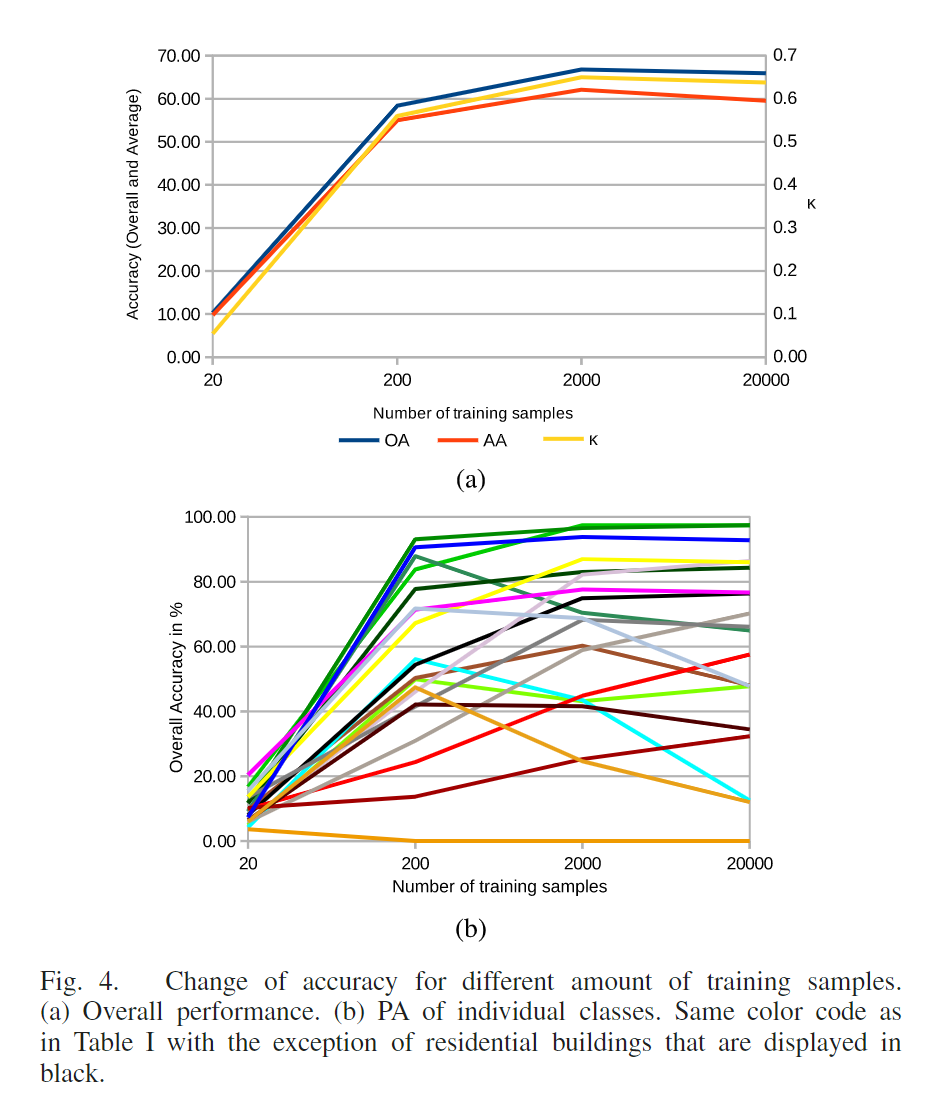
第一个实验:通过在不同数据源(及其组合)上训练随机森林来评估分类性能。对于较小的数据集,随机森林的方差往往很高,随机森林趋于稳定需要大量决策树,因此本文重复了五次相应的实验并将结果平均。