摘要
最近,基于图像区域的上下文推理已显示出场景分割的巨大潜力。本文通过提出Graph Interaction unit(GI unit)和 Semantic Context Loss(SC-loss),探究如何利用语义知识来促进图像区域的上下文推理。 GI单元能够增强卷积网络的特征表示,并能让每个样本自适应地学习语义一致性。具体来说,首先将基于数据集的语言知识被纳入到GI单元中,以促进视觉图的上下文推理。然后演化的视觉图特征被映射到每个局部特征中,以增强场景分割的辨别力。SC损失进一步改进了GI单元,以增强基于样本的语义图的语义表示能力。本文进行了广泛的消融实验,以证明本文方法的有效性。本文的GINet在Pascal-Context和COCO Stuff数据集上都优于同期方法。
介绍
场景分割是一项具有挑战性的任务,在机器人感应和图像编辑等各种应用中具有巨大的潜在价值。它将图像中的每个像素分类为指定的语义类别,包括目标(例如,自行车,汽车,人)和背景(例如,道路,长凳,天空)。建模上下文信息对于场景分割非常重要。最近,使用图像区域进行上下文推理体现了场景分割的巨大潜力。许多方法被提出,这些方法从视觉特征中学习图的特征表示。其中,点表示区域中的像素簇,边表示特征空间中这些区域的相似性或关系。这样,在交互图空间中进行上下文推理,然后将演化后的图映射到原始空间以增强用于场景分割的局部特征。
本文不仅仅对二维输入的视觉图特征进行上下文推理,而是设法利用语义知识(比如语义相关性和标签依赖性)跨位置共享外部语义信息,这些信息可以促进视觉图的上下文推理。具体而言,我们提出了一个图交互单元(GI单元),该单元首先将基于数据集的语义知识整合到视觉图的特征表示中,然后将演化的视觉图特征重新映射到每个位置的特征中,用于增强判别能力。如下图1所示,将外部知识建模为语义图,该语义图由具有语言实体(如杯子、桌子、桌子)和具有实体关系(如语义层、并发、空间交互)的边缘的顶点形成。GI单位显示了视觉图和语义图的交互。此外,本文引入了一个语义级的上下文损失(SC损失),它用来自适应地增强基于样本的语义图的语义表示能力——增强出现在场景中地类别,抑制未出现在场景中地类别。
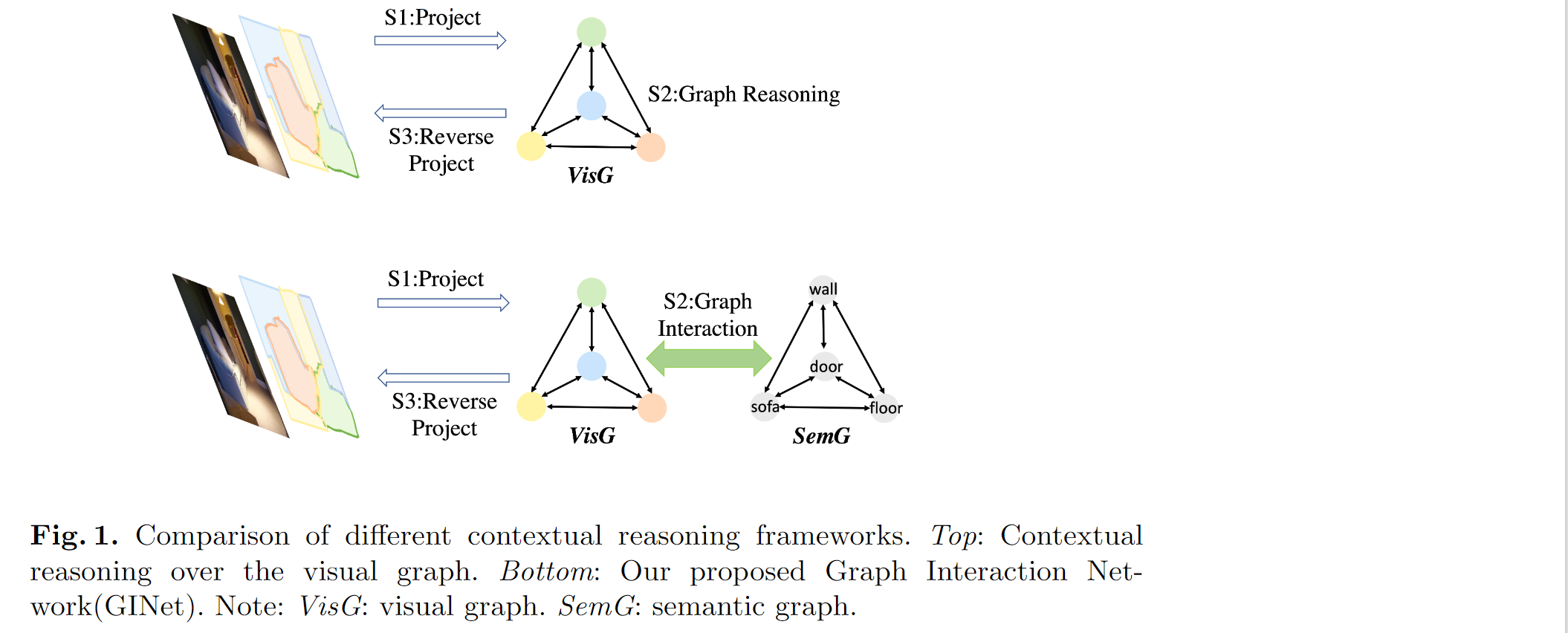
言而言之,本文对视觉图和先验语义图进行推理。语义图用于促进上下文推理,并从视觉图中生成基于样本的语义图。
本文贡献
1、本文提出了一种新颖的图交互单元(GI unit)进行上下文建模,该单元结合了基于数据集的语义知识,以促进视觉图的上下文推理。此外,它还学习基于样本的语义图。
2、本文提出了一种语义上下文损失(SC-loss)来规范训练过程,该方法增强出现在场景中的类别,抑制不在场景中出现的类别。
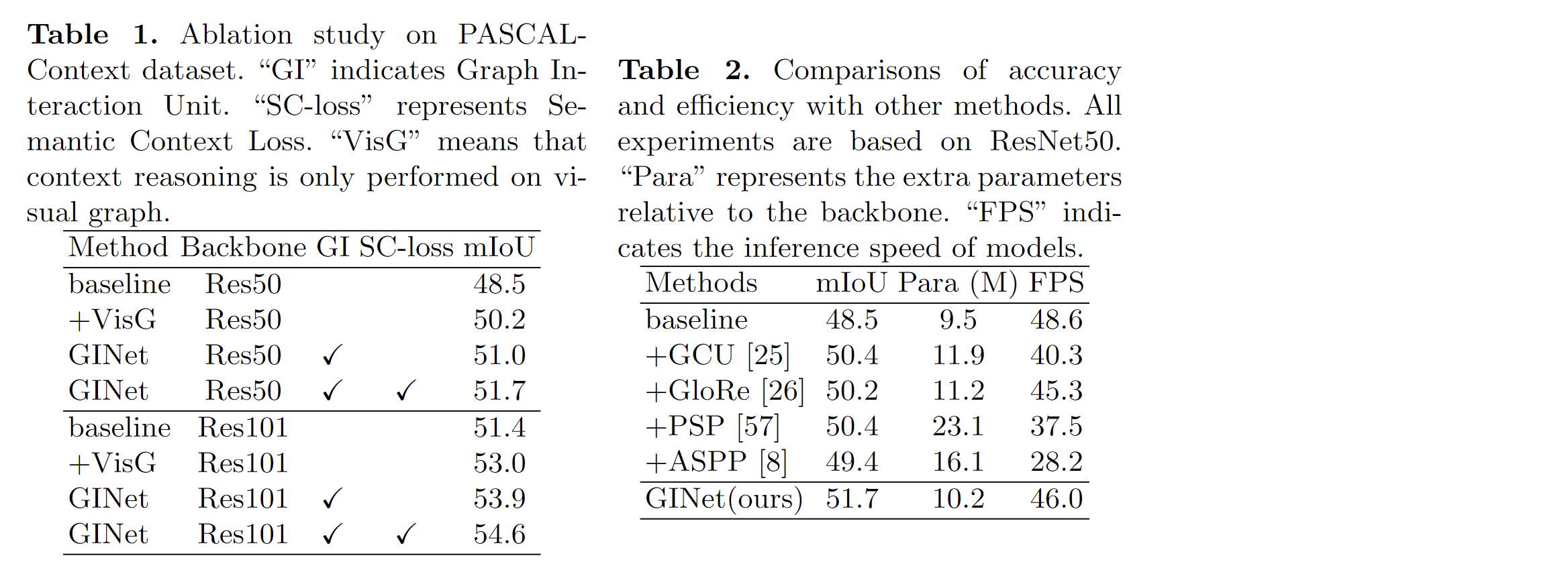
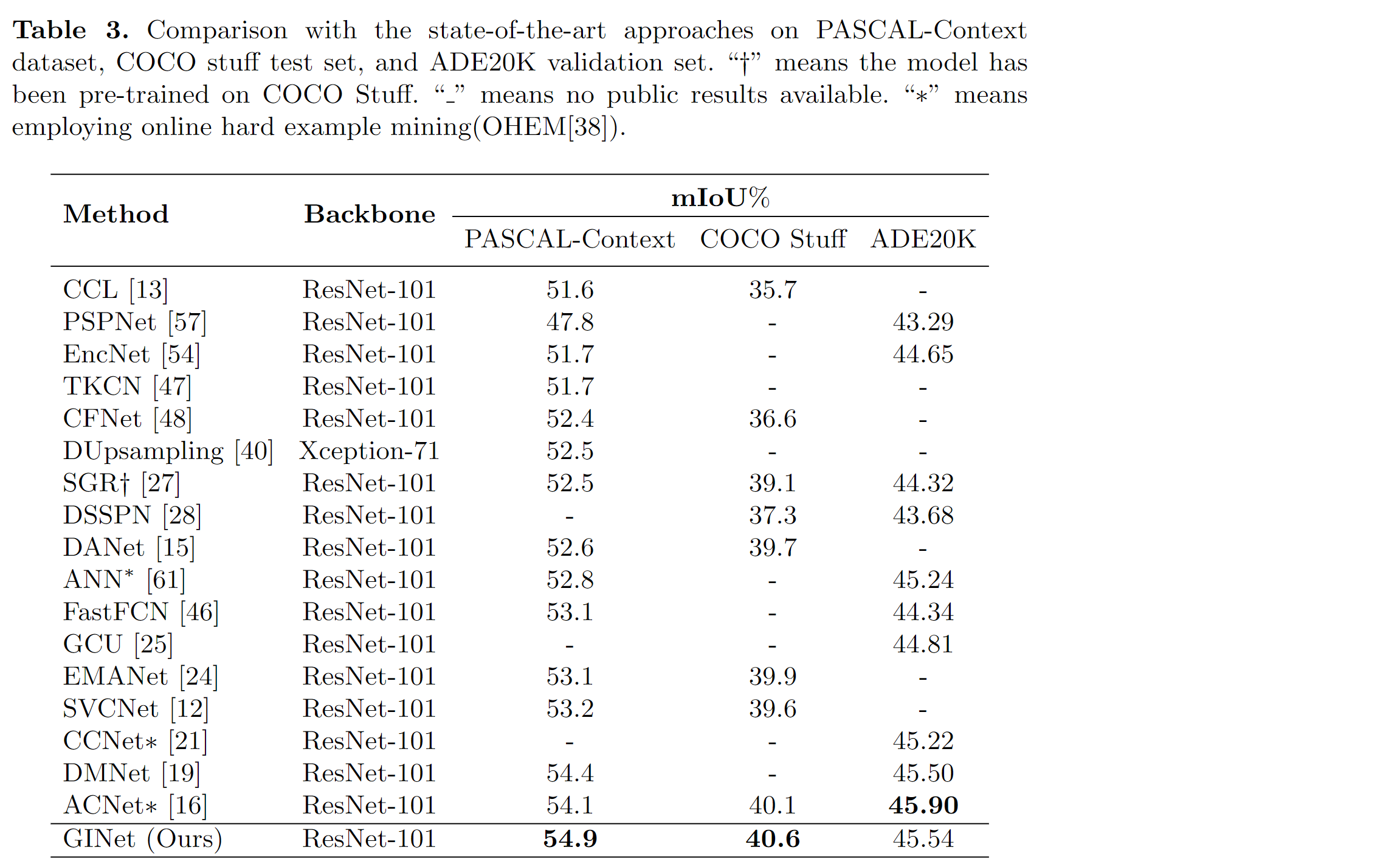
3、本文基于GI unit和SC-loss,提出了一个图交互网络(GINet)进行场景分割。与最新方法相比,本文模型在Pascal-Context和COCO Stuff数据集上显著提高了性能,并在ADE20K数据集上拥有良好地性能。
方法
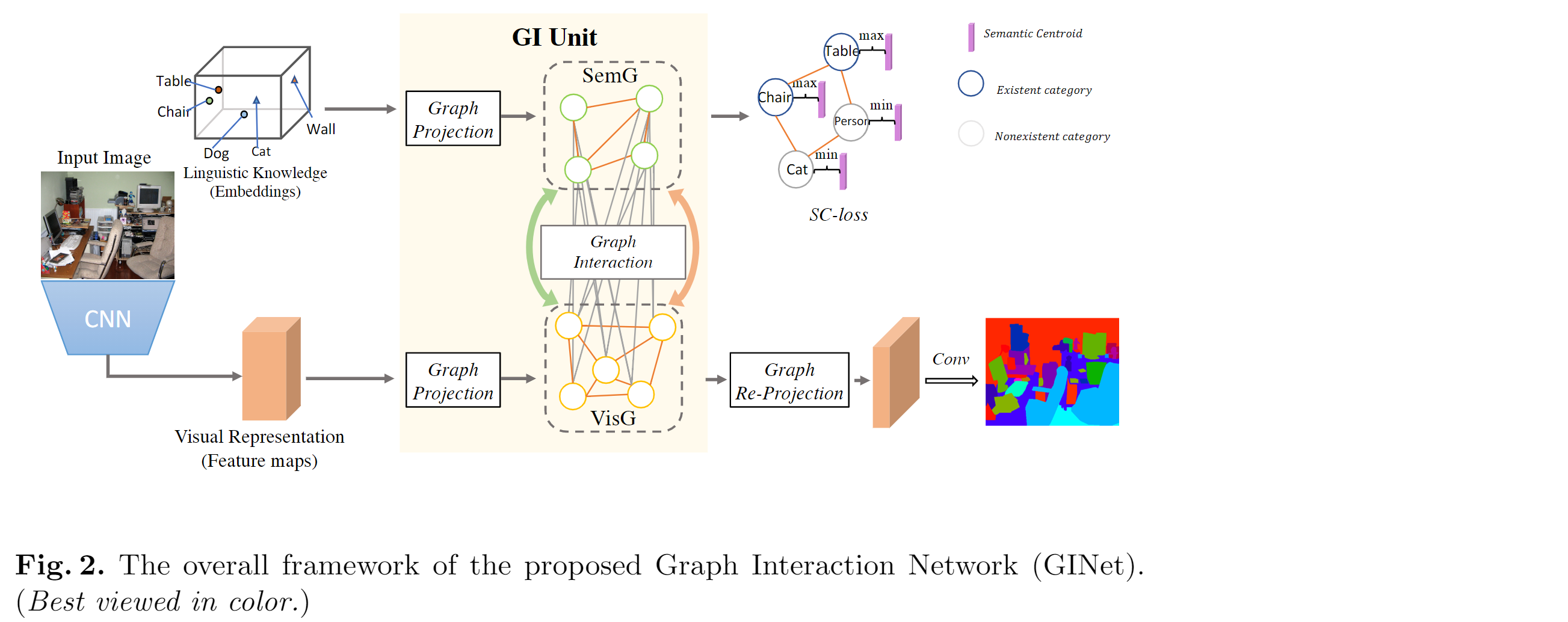
如上图所示:
首先采用经过预训练的ResNet作为backbone:将图片输入resnet得到 视觉特征(Visual Representation) (特征图);
同时:对数据集以类别的形式提取 语义知识(Linguistic Know) ,并将其输入词向量以实现语义的特征表示。
将 视觉特征(Visual Representation)经过图映射得到 视觉图(VisG) ;语义知识(Linguistic Knowledge)经过图映射得到 语义图(SemG)
VisG: 体现视觉区域的依赖关系;SemG: 体现语义相关性和标签相关性
在GI单元中 图交互(Graph Interaction)操作 ,其中语义图用来促进视觉图的上下文推理,并指导生成从视觉图中提取的基于样本的语义图。
然后 由GI单元生成演化后的视觉图,生成的视觉图通过 重新映射(Graph Re-Project) 操作,来增强每个局部视觉特征的判别能力;
在训练阶段,语义图被 SC loss 更新和约束
最后,使用1 * 1的 卷积 ,然后进行简单的双线性上采样以获得场景分割结果。
图交互单元(Graph Interaction Unit)
GI单元的目的是结合基于数据集的语义知识来增强局部特征表示。首先,GI单元将视觉特征和语义特征作为输入,通过生成视觉图和语义图进行上下文推理。其次,在两个图之间进行图交互,以通过视觉节点和语义节点的相似性来演化节点特征。
图的构造(Graph Construction)
第一步 是将初始的视觉特征和语义特征映射到交互空间。
设视觉特征 X∈R(L * C),L = H * W;视觉图的特征表示 P∈R(N * D), N:节点数,D:每个节点的特征维度;转置矩阵 Z∈R(N * L),Z为局部特征X到高层特征P的转置矩阵。其中:P = ZXW —— W∈R(C * D),W为权重
第二步 定义一个基于数据集的语义图。
设语义图特征 S∈R(M * D),S对语义相关性和标签依赖性编码,M:节点数(=数据集的类别),D:每个节点的特征维度;
本文使用现成的词向量获得每个类别i∈{0,1,…,M-1}的语义特征:l
i∈R(K),K=300;然后,MLP层用于调整语义embedding以适应视觉图的推理。转换过程:S
i= MLP(li), i∈{0, 1, …, M-1},Si指每个类别的节点特征
图交互(Graph Interaction)
经过图的构造得到了SemG和VisG。SemG和VisG首先分别evolve,然后再进行交互:语义到视觉(S2V)和视觉到语义(V2S)。
首先,在VisG上执行图卷积,以获得与SemG交互的evolved图特征 P’:P’ = f((Av + I) P Wv)。
A
v∈R(N * N):邻接矩阵,被随机初始化,并使用梯度下降法更新。I:单位矩阵。Wv∈R(D* D):可训练的参数;f:非线性激活函数
通过对VisG进行推理,更新节点表特征以获取更多的上下文信息并与SemG进行交互。然后对SemG进行类似的图卷积:S’ = f((As + I) S Ws)。
A
s∈R(M * M):可学习的邻接矩阵或co-occurrence matrix。I:单位矩阵。Ws∈R(D* D):可训练的参数;f:非线性激活函数
S’ 通过获取邻近节点的特征信息,我们可以提高每个语义节点的特征表示。
S2V :利用演化的SemG来促进VisG中P’的上下文推理
具体来说,为了探索VisG和SemG的两个节点之间的关系,本文将它们的特征相似度计算为导向矩阵G^s2v^∈ R(N * M) 。对于VisG中P的一个节点pi‘∈ R(D)和SemG中的一个节点sj’∈R(D),我们可以计算出指导信息G
i;j^s2v^ ,它表示SemG中的节点sj’对节点pi’的权重分配: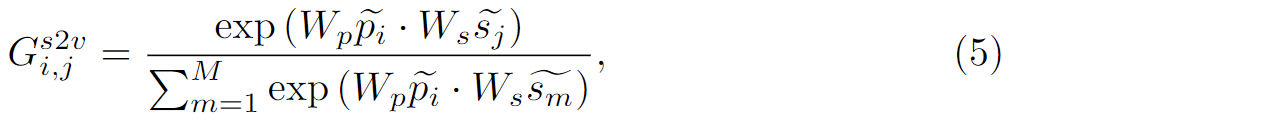

其中i∈{1, …, N},j∈{1, …, M},W
p∈R(D/2 * D),Ws∈R(D/2 * D);在获取导向矩阵G^s2v^后,便可以从SemG中增强VisG的特征:
其中:W
s2v∈R(D * D)为可训练权重,βs2v∈R(N)为0初始化的可学习向量,可通过梯度下降法更新。这里的求和可被求均值,最大值或拼接算法代替。由于导引矩阵Gs2v的使用,本文有效地构建了视觉区域与语义概念之间的相关性,并将相应的语义特征纳入了视觉节点的特征表示中。V2S :与等式5类似,构造G^v2s^∈ R(M * N) ,令i∈{1, …, M},j∈{1, …, N}:
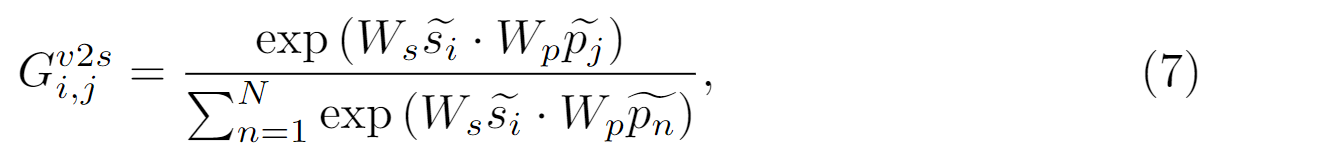
以及更新SemG的图特征:
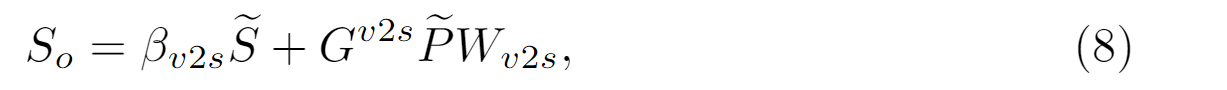
同理::W
v2s∈R(D * D)为可训练权重,βv2s∈R(M)为0初始化的可学习向量通过组合S2V和V2S步骤,提出的GI单元使整个模型能够学习更多的可辩别的特征,有助于逐像素的分类,并为每个输入图像生成一个语义图。
IG单元输出(Unit outputs)
GI单元有两个输出,一个是基于样本的SemG,另一个是通过语义信息增强的VisG。 VisG的演化节点表示可用于进一步增强每个像素特征的判别能力。借助前人的方法,本文重用投影矩阵Z将Po反向投影到2D像素特征上。对给定VisG的节点特征Po∈R(N * D),反向投影(Graph Re-Projection)可以表示为:

Wo∈R(D * C)是一个可训练权重矩阵,它将节点的特征表示从R(D)转换到R(C); Z^T^∈R(L * N)为Z的转置矩阵。
语义上下文损失函数(Semantic Context Loss)
SC-loss目的:增强出现在场景中的类别,抑制未出现的类别
本文先对每个类别定义一个可学习的语义重心 ci∈R(D);然后,对一个SemG中So‘ 的每个语义节点si’∈R(D),定义vi = sigmoid(si’ * vi’)∈[0, 1),vi使用BCE轮式函数。SC-loss最大程度地减少了语义图中的节点特征与不存在类别的语义质心之间的相似性,并使现有类的相似性最大化。具体的SC-loss表示如下:
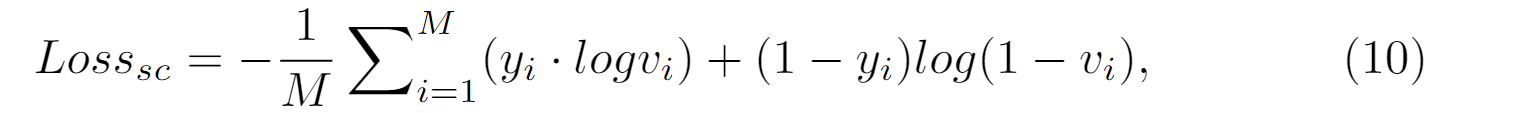
yi∈{0, 1}为每个类在真实场景中的存在情况。
本文还设置了连接到backbone的全卷积层去获得分割结果,因此总损失由三个部分组成:
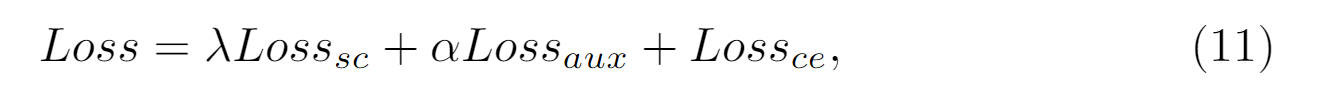
实验