摘要
本文提出了non-local操作作为捕获远程依赖的构建块。non-local操作以所有位置特征的加权和来计算某个位置的响应。该模块可以插入许多计算机视觉体系结构中。在视频分类的任务上,我们的non-local模块在Kinetics和Charades数据集上可以竞争或优于当前的竞争获得者。在静态图像识别中,我们的非局部模型可改进目标检测/分割以及在COCO数据集上的姿态估计。
介绍
模型优点:
non-local operations capture long-range dependencies directly by computing interactions between any two positions, regardless of their positional distance
non-local操作直接通过计算两个位置的相互影响捕获长距离依赖,而不管它的位置距离
As we show in experiments, non-local operations are efficient and achieve their best results even with only a few layers
non-local操作是高效的,只有几层的网络就能实现最好的结果
our non-local operations maintain the variable input sizes and can be easily combined with other operations (e.g., convolutions as we will use).
non-local操作保持了可变的输入大小,并且很轻松地应用到其他操作(如卷积)
论文显示了non-local操作在视频分类任务中的有效性。在视频中,空间和时间的远距离像素之间会发生远程交互。在我们基本模块中,一个单个的non-local模块能够以前馈的方式捕获这些时空依赖。non-local神经网络(含有几个non-local模块)在视频分类任务中比2D/3D卷积更精确。除此之外,non-local的计算复杂度比三维卷积更低
Non-local 神经网络
1 公式
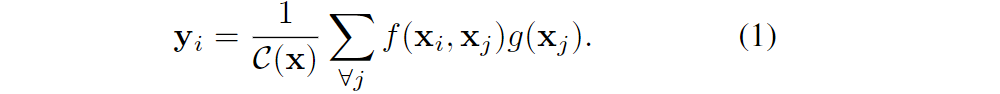
i:计算响应的输出位置(空间/时间/时空)的索引;j:枚举所有位置的索引;
x:输入信号特征(图像、视频等);y:输出信号特征;
f(xi, xj):计算i到j的关系标量;g(xj):计算位置j的输入信号的特征;
C(x):结果经过C(x)归一化;
公式(1)中可以看出:non-local就是考虑了所有位置j(卷积和recurrent操作是局部的)
non-local vs 全连接
non-local基于不同位置的相关性计算(x
i–> xj);fc基于学习的权重(xi–> yi)non-local可以加在卷积层/递归曾;fc加载末尾
2 实例化
- 为了简化,设W
g为学习的权重矩阵,g(x)为线性嵌入的形式:
设高斯函数f如下,C(x)与嵌入式高斯函数一样:
嵌入式高斯函数:高斯函数的简单扩展是计算嵌入空间中的相似度,本文中如下
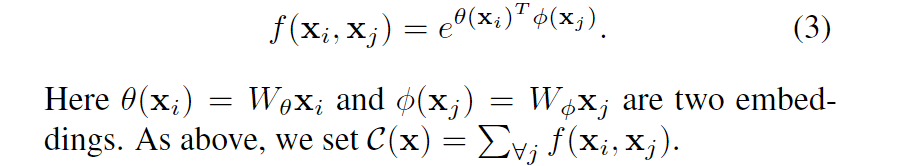
自注意力模块是嵌入式高斯模型中的一种非局部操作的特例,我们由此得出:对于给定的i,1/C(X) f( x
i, xj)是沿着维度j的softmax计算。因此自注意力机制的表示形式:本文工作将最近的self-attention模型与经典的非局部均值联系起来,将self-attention网络拓展到non-local网络,用于cv的图像/视频识别。尽管如此,由于softmax,作者也觉得attention对本文的研究不是必须的,具体见下文两点。
设f为一个点乘相似度, C(x)为归一化函数,N为x位置的数量:
这样设置归一化能简化梯度计算,以及可以保证可变大小的输入。在点乘相似度与嵌入式高斯模型的不同指出在于softmax的存在,它扮演了激励函数的角色
设f为一种拼接形式,[ . , . ]:拼接;w
f:权重向量——用于将拼接向量投影到标量;同样C(x) = N以上四种设定显示了non-local的灵活性。我们相信可替代的版本是可能的,并且可以改善结果
3 non-local模块
根据公式(1),我们定义non-local模块:
“+xi“:残差连接;残差连接允许我们在任何预训练的模型中插入新的non-local块,而不会破坏它本来的形式;f函数的高斯和点乘算法都可以简单地通过矩阵乘法完成,而拼接算法则直接concat(如下图2):
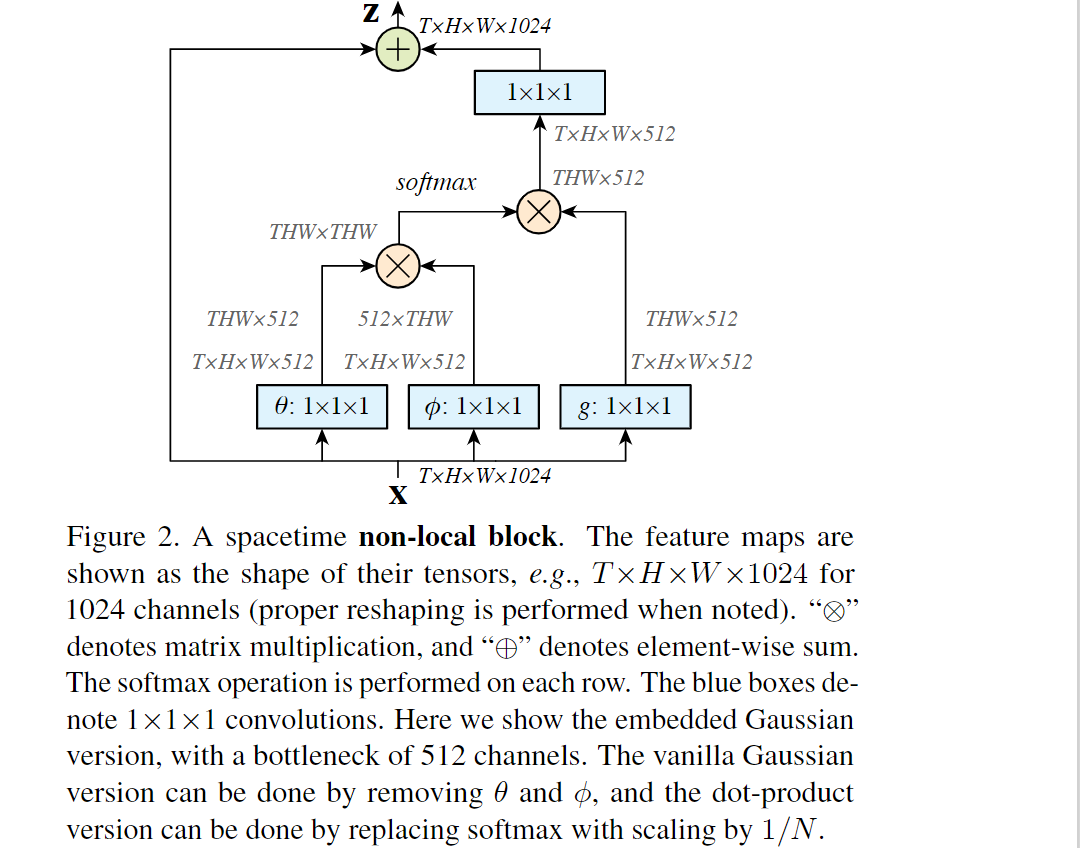
提升模型的效率:
如上图2,设置W
g,Wθ,Wφ的通道数为x中通道数的一半,权重矩阵Wz的通道与x保持一致(保证输出维度一致)使用下采样的方法——将公式(1)的x通过池化等方法下采样一下,或在上图2中 φ/θ 后加一个最大池化层
视频分类模型
2D ConvNet baseline (C2D)
为了隔绝non-local网络与三维卷积网络的时间影响,我们构造了二维的基本结构,其时间维度得到简单处理(池化),如下表1,卷积核为二维,用于逐帧处理输入。模型直接初始化其权重经过ImageNet数据集预训练的ResNet权模型。 ResNet-101以相同的方式构建。

Inflated 3D ConvNet (I3D)
通过增加卷积核的维度,表1中的C2D模型可转为3D卷积模型。比如(k, k)——>(t, k, k)。其中,(t, k ,k)的卷积核的权重由(k, k)卷积核初始化,t平面的权重再重新缩放到1/t。如果视频由时间上重复的单个静态帧组成,则此初始化将产生与在静态帧上运行的2D预训练模型相同的结果。由于三维卷积的计算复杂性,我们只能每两个残差快扩展一个卷积核,扩展层数太多会让结果下降。conv1 卷积核扩展为(5, 7, 7)
训练
我们使用再ImageNet上预训练的模型,使用32帧输入短片微调模型。这些剪辑通过从原始全长视频中随机裁剪64个连续帧,然后每隔一帧丢掉所得。每帧图片大小为224×224——先将原视频像素([256,320])以短边缩放,然后随机裁剪所得。mini-batch=8,epoch=400k,lr=0.01(每150k个epoch乘以0.1),momentum=0.9,weight decay=0.0001,全局池化后使用dropout(0.5),启用BatchNorm微调模型。与微调ResNet不一样,我们将BN打开。
我们采用[20]中的方法来初始化在non-local模块中引入的权重层。仅增加一个BN层在最后的1×1×1层之后,BN层的参数初始化为0
实验结果
- 训练过程曲线
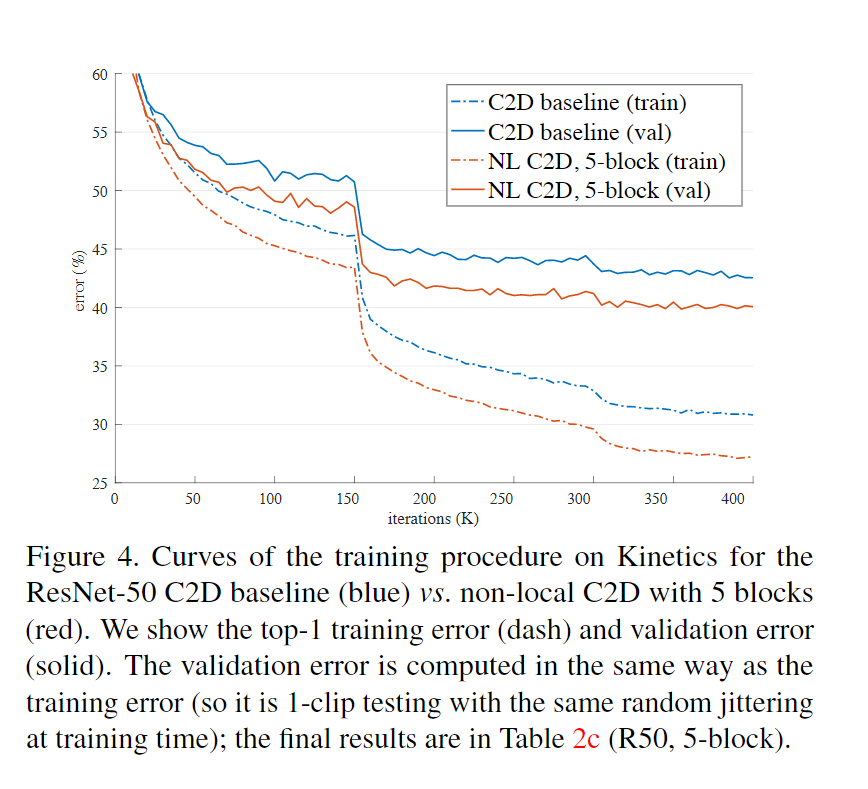
non-local模块的实例——网络可学习到有意义的关系线索,而不管空间和时间上的距离


实验结果:C2D vs I3D
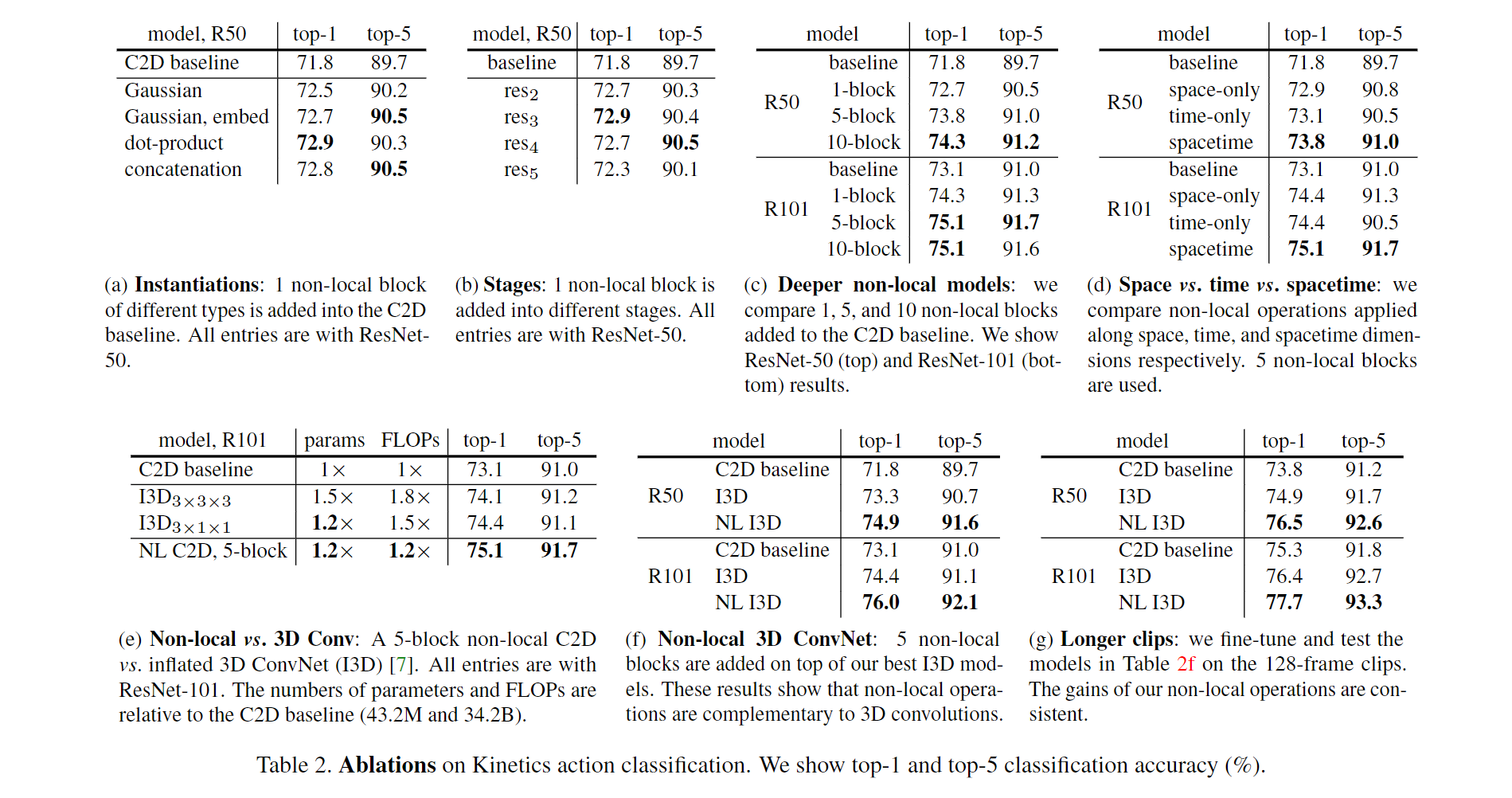
实验结果:I3D作者[7] vs Kinetics 2017获胜者[3]