
摘要
对于图像和视频识别来说,学习捕获长距离的关系是基本的。已存的CNN模型通常依赖于增加深度来建模这种低效的关系。在本文中,我们提出了“双注意力模块”——一种新的模块——能够聚集并传播信息的全局特征,这种全局特征来自输入图像/视频的spatial-temporal空间,以便使后续的卷积层能够访问来自整个空间的特征。双注意力机制分为两步:第一步通过second-order(二阶)注意力将整个空间的特征聚集到一个紧凑的集合中;第二步经过另一个注意力自适应性地选择特征并将特征分配到每个位置。所提的双注意力模块能够很方便地插入到已经提出的深度神经网络之中。我们对图像和视频识别任务进行了广泛的消融研究和实验来评估我们模型的性能。在图像识别任务中,含有双注意力模块的ResNet-50在ImageNet-1k的数据集上优于ResNet-152结构,它的参数数量减少了40%以上,FLOP也减少了。在行为识别任务中,我们所提的模型在Kinetics和UCF-101上取得了优秀的结果,并且本文所提算法的效率远高于最近的工作。
1 介绍
在这篇论文中,我们通过引入一项新的网络结构来克服计算复杂等这些问题。这个结构使卷积层能够立即从其相邻层感知整个spatial-temporal空间(输入帧的整个特征图和视频序列中的完整spatial-temporal特征)。核心思想是首先将空间中的关键特征聚集到一个紧凑的集合,然后自适应地将他们分配到每个位置。这个结构即使没有大的感受野,后续的卷积层也可以从整个空间感知特征。我们将双注意力块表示为A²-block,网络表示为A²-Net。
Contributions:
1、提出了一种通用的公式——经由通用的聚集和分配功能来捕获远程特征的相互依耐性
2、提出A²-block来聚集和分配远程特征,这是一种有效的结构来捕获second-order特征统计并进行自适应地特征分配。这个模块在低计算量和低内存地情况下建模远程特征的相互依赖,极大地促进了图像/视频的感知性能。
3、对所提的A²-Net进行广泛的消融研究并证实其优越的性能。
2 方法
设计卷积操作来专注局部邻域,因此无法“感知”spatial/temporal空间,比如整个输入帧或跨多个帧的一个位置。因此CNN通常采用多个卷积层或循环单元来捕获输入的全局特征。同时,最近显示,自注意力和二阶池化的相关操作在多种任务中工作得很好。本文所提结构能够收集全局特征并将其分配到输入的每个spatial-temporal位置,以便帮助后续的卷积层立即感知整个空间并捕获复杂的关系。
设X:spatial-temporal(3D)卷积层的输入;c:channel数;d:时间维度;h,w:空间维度 ; vi:对每个时空输入位置的局部特征;zi:操作的输出——首先收集整个空间的全局特征,然后再考虑局部特征vi,并将其分配到每个输入位置i,其zi:
为了应对前人出现的缺点,本文提出的A²-block(如图a),其全局信息首先由二阶注意力池化收集(而不是一阶平均池化),然后根据当前局部特征 vi 的需要,通过二阶注意力机制自适应地分配所收集的全局特征。使用这种方式,一组紧凑的特征就能够捕获更复杂的全局关系,并且每个位置都能收到其自定义的全局信息,这个全局信息与现存的局部特征互相补充,有助于每个位置学习更复杂的关系。
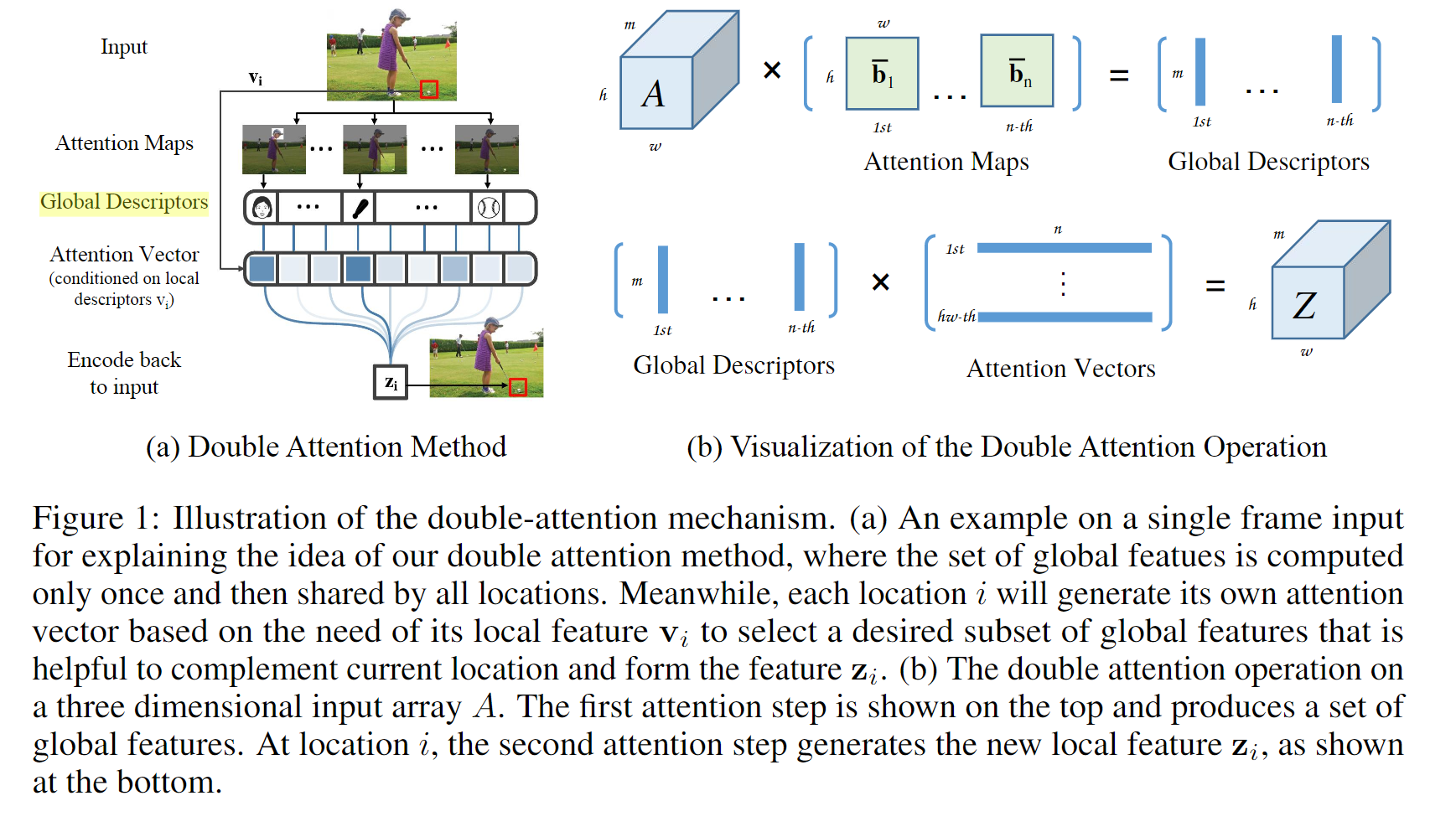
2.1 第一个注意力步骤:特征聚集矩阵G——图1(b)的第一步
最近的工作有使用双线性池化去捕获特征的二阶统计并生成全局表示。与仅仅计算一阶统计的常规的平均池化和最大池化相比,双线性池化能更好地捕获和保护复杂关系。事实上,双线性池化给出了来自外部乘积(所有特征向量对(ai , bi ))的二阶特征的一个sum池化:
其中:;A和B可以是同一层或不同层的特征图;将其引入双线性池化的输出变量G:
其中:双线性池化的输出:
bn是一个dhw维的行向量;说明双线性池化不仅仅是计算二阶统计量,其输出G实际上是一堆visual primitives,每个gi 通过收集由bi 加权的局部特征。因此我们提出了一种新的基于注意力的特征聚集操作——将softmax分类器应用于B以确保有效的特征加权向量:
二阶注意力提供了有效的方法来收集关键特征:①全局特征—— 当bi在所有位置都有参与时,比如纹理和光照;②特定语义—— 当bi 在稀疏的特定位置有参与时,如物体。然而,我们应用注意力池化去收集不同位置的视觉图元,使用softmax将其放进一个全局描述符中,并且不需要低秩约束。
2.2 第二个注意力步骤:特征分解——图1(b)的第二步
从整个空间收集特征之后是将其分配到输入的每个位置,这样即使卷积核很小,后续的卷积层也能感知全局信息。
与SENet分配相同的全局特征给每个位置不一样,我们提出了一种更灵活的方法——基于每个位置特征vi (如图1(a))的需要自适应地分配。这样,每个位置能选择与当前特征互补的特征,这种方式使得训练更容易、能帮助捕获更复杂的相关性。其实现通过选择Ggather (X)的特征向量的子集完成:
上公式为所提的对于特征选择的软注意力。我们应用softmax函数将vi 归一化为具有单位和的vi ,这发现其收敛性更好。与产生注意力map的方式相似,注意力权重向量集也由一个后跟softmax生成器的卷积层产生,如,W为包含这层的参数
2.3 双注意力模块
图:
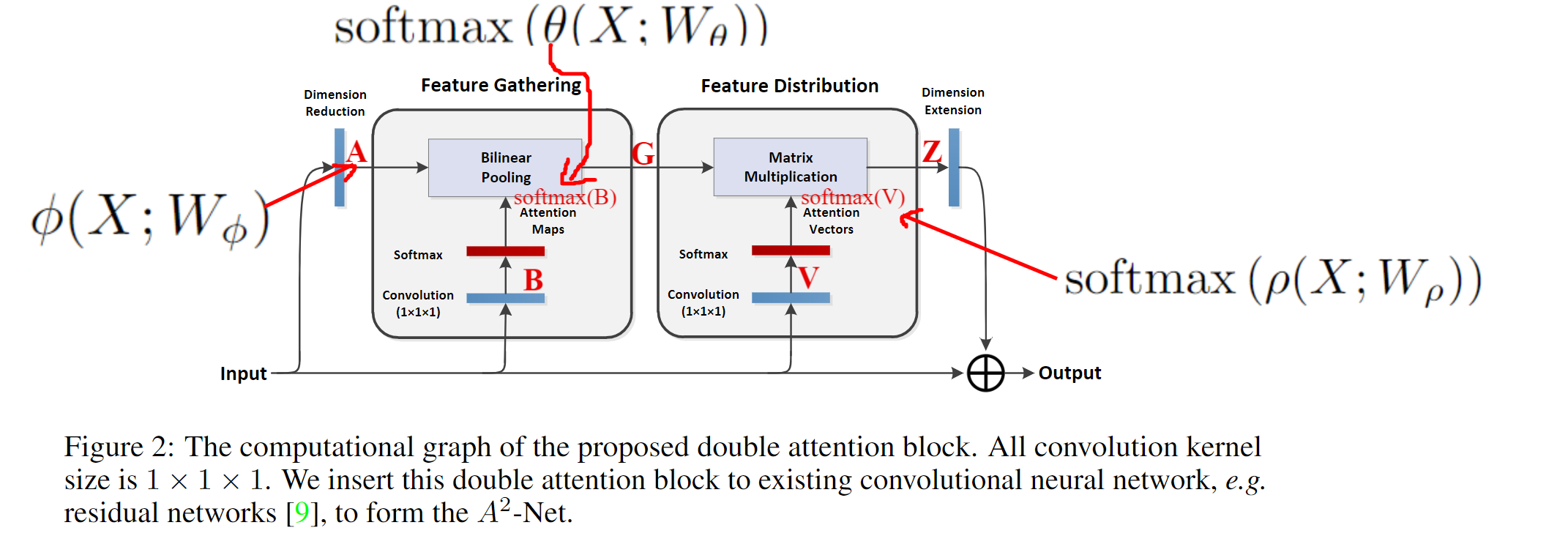
双注意力操作的公式:
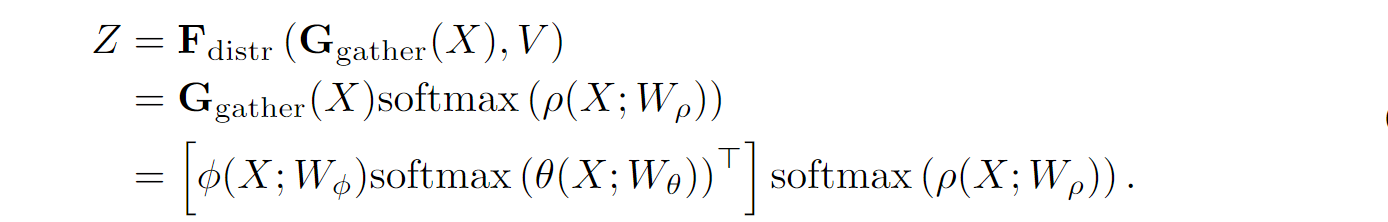
其中,A、B、V:基于输入特征数组X的三个不同卷积操作所生成,当然需要的话X还要经过softmax分类器;Z:两个需要reshape和转置运算的矩阵乘法得出
此处,在末尾添加了一个附加的卷积层,以扩展输出Z的通道数,从而可以通过逐元素加法将其编码回输入X。训练过程使用带链式规则的自动梯度计算损失函数的梯度。
双注意力操作的公式还可以如下:
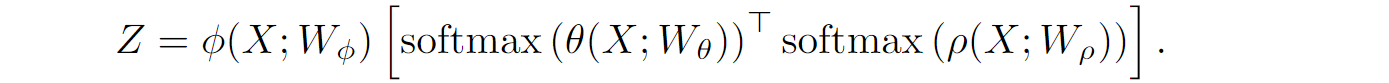
以上两个公式的输出一样,但是拥有不同的计算复杂度和内存消耗。
3 实验
3.2 消融研究
在单个的nonlocal block和本文的双注意力模块比较如下表,该块放于某阶段的第二个残差单元之后。本文模型性能增强,额外消耗很少。但是顶层加入本文模块的性能更强,这可能是因为顶层提供了更多的语义抽象表示形式,这些表示形式适合提取全局视觉图元( visual primitives )。
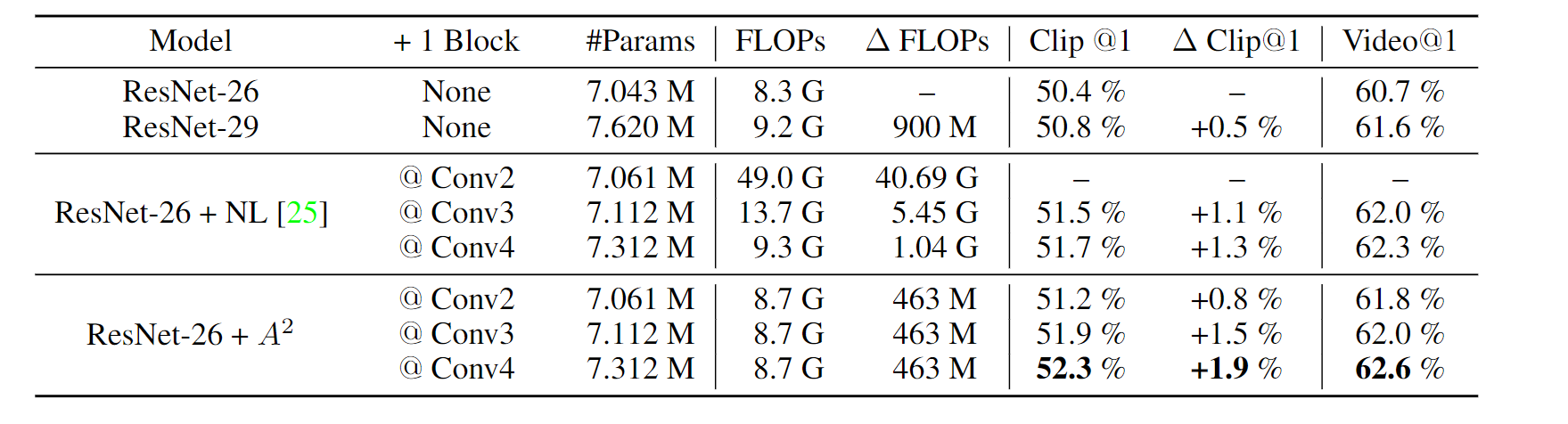
在多个nonlocal block和本文的双注意力模块比较如下表:精度提高,FLOPs消耗得更少;同时,将block加到不同阶段比同样的阶段能获得更好的精度

3.3 图像识别

3.4 视频识别
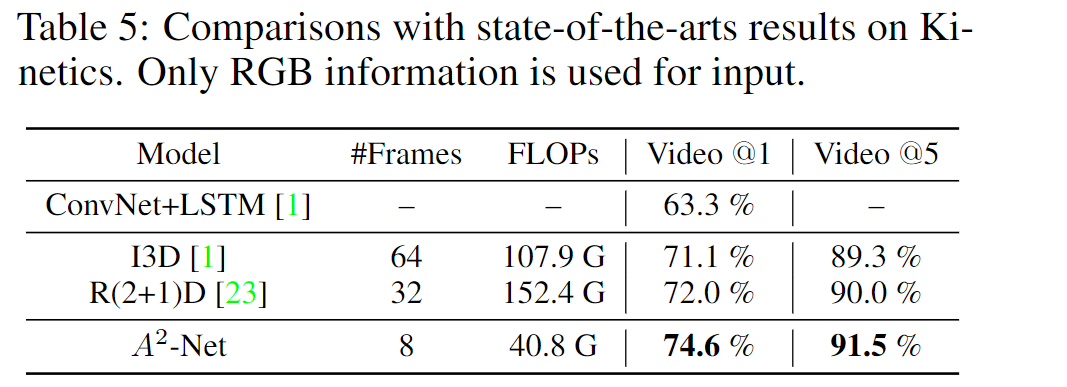
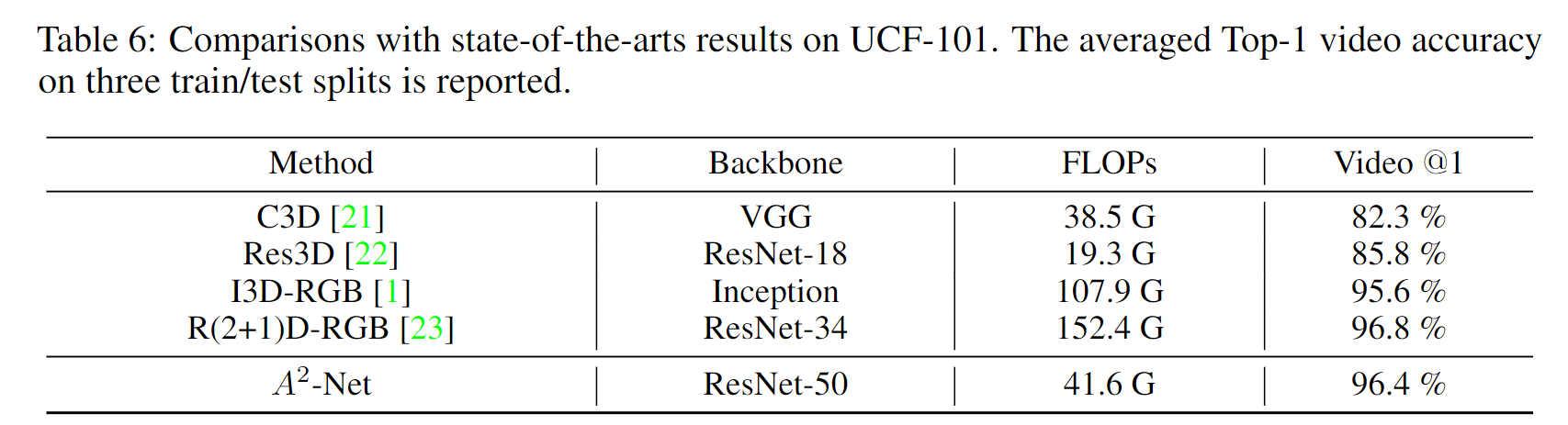
4 总结
本文,我们提出了针对深层CNN的双重关注机制,以克服局部卷积操作的局限性。所提出的双重注意力方法有效地捕获了全局信息并使用两步注意力的方法将其分配到每个位置。我们很好地用公式表示了所提的方法,并将其实例化为轻量级模块,可以很容易地将其插入到现有的CNN中,而所需的计算量却很少。我们在ImageNet-1k,Kinetics和UCF-101的许多基准数据集上进行了广泛的消融研究,证实了A^2^ -Net在2D图像识别任务和3D视频识别任务上的有效性。未来,我们探索将双重注意力整合到最新的紧凑型网络结构中,以表达更小的,移动友好的模型。